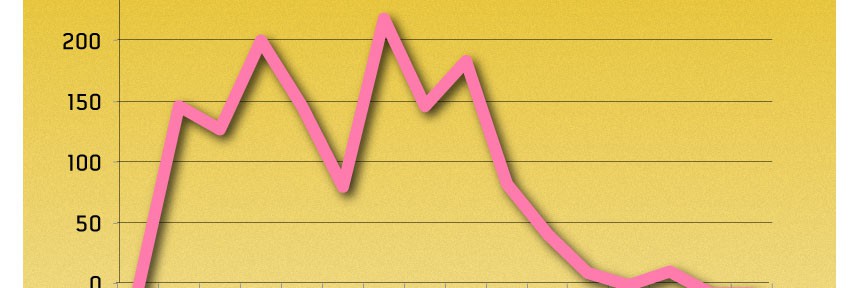
Så här twittras det om almedalen, uppdelat i 10minutersperioder. Jämförelse mellan 2013 och 2012. Själva datan finns i ett google spreadsheet du kan hitta här.
En lite mer färgglad version ser ut så här: 
Så här twittras det om almedalen, uppdelat i 10minutersperioder. Jämförelse mellan 2013 och 2012. Själva datan finns i ett google spreadsheet du kan hitta här.
En lite mer färgglad version ser ut så här:



Helgen tillbringade jag på en minikonferens tillsammans med en lång rad rejält begåvade och trevliga personer. Men förutom prat om allt från zombieapocalyps till systemteori så blev det lite hackat. Jag slängde upp ett API och @peppelorum satte ihop ett Chrome-extension för Twittercensus. Resultatet gör det möjligt att se vilket kluster en given person tillhör, direkt i flödet på twitter.com. Alltså ett enkelt verktyg för att se vilka som twittrar om ett ämne.

Vila muspekaren över rutan för att se vad klustret heter och ett klick på den lilla fyrkanten leder dig direkt till aktuellt konto i den stora twittercensuskartan.

Tillägget funkar även i sök – vilket innebär att du snabbt kan få en uppfattning om i vilka grupper ett ämne diskuteras. Användbart vid en rad olika tillfällen.

Chrome extensionet finns att ladda hem här. Koden finns i Github.
Twitter håller på att stänga ner sitt API 1.0 till förmån för version 1.1. Men det handlar inte bara om en uppgradering – samtidigt gör de om själva “rate limit”-systemet, alltså hur ofta och hur många gånger varje klient eller app får ställa frågor till Twitter. Sanningen är att det är flera år sedan de började strypa tillgången till API:t, och den typen av vitlistade konton som vi har (och som möjliggör att ställa 20 000 frågor per timme) har inte har delats ut på flera år. Så egentligen är det inte själva API-uppgraderingen som är problemet, utan snarare att samtidigt som Twitter fasar ut API1.0 så försvinner alla vitlistade konton.
Vad är det så som är så speciellt med behoven i Twittercensus? Jo, till skillnad från andra mätningar tittar inte Twittercensus alls på realtidsdata (det Twitter erbjuder via sitt “streaming API”). Istället fokuserar Twittercensus på relationer, och följer ett kontos alla relationer för att söka efter ytterligare svenskspråkiga konton. Det spelar alltså ingen roll om en person inte har skrivit sedan 2006 eller tweetar under tiden vi gör mätningen – har kontot skrivit på svenska ska den fångas in. Oavsett om vi har tillgång till alla Tweets som skrivs i hela världen så hjälper inte det, vi behöver fortfarande hämta alla relationer och de senaste tweetsen för alla konton från REST API:t. Det innebär minst två frågor till Twitter per konto (och många fler om konton har många följare eftersom maximalt 5000 relationer kan hämtas per fråga). Det går att köpa data från olika återförsäljare som samlar. Men de är alla fokuserade på realtidsdata eller tweets – och ännu har jag inte hittat någon som kan sälja den informationen som behövs för Twittercensus (alltså relationsdata).
De nya begränsningarna som införs kommer alltså att gälla för oss. Det innebär att varje timme kan vi ställa 60 frågor om följare, 60 frågor om följer och hämta tweets för 720 konton. Förutsatt att kontona i fråga följer och följs av mindre än 5000 kan vi scanna 60 svenska konton per timme, samt göra språkanalyser av 720 konton. Med tanke på att senaste Twittercensus sammanlagt scannade analysera 6 171 929 twitterkonton och hämtade relationer från 475 474 konton skulle datainsamlingen ta 357 dagar.
Men en tanke har redan börjat gro [och som föreslogs av @beantin]: vad sägs om att vi distribuerar ut själva datainsamlingen på SETI-vis? På kvällen surfar ni in på en webbplats och lämnar datorn på. En dator skickar information om vilka konton som ska scannas och klienterna rapporterar in resultaten.
Eller så hjälper någon till med en kontakt på Twitter som förstår varför Twittercensus är ett häftigt projekt som borde få fortsätta! Eller så tar vi gärna mot andra tips och idéer!
Vill du kolla hur många gånger en sida/artikel delats på Facebook?
Ange adressen http://graph.facebook.com/ direkt föjt av hela URL:en till sidan du vill kolla.
http://graph.facebook.com/http://www.dn.se/kultur-noje/basta-beatrice-ask
I retur får du antalet delningar omnämnanden.
{
"id": "http://www.dn.se/kultur-noje/basta-beatrice-ask",
"shares": 69832
}
[UPDATE] Observera att detta inte är siffran på faktiska delningar utan delningar, gillningar och kommentarer. Den rena siffran på delningar får du ut med den här sökningen. Kopiera och klistra in i adressfältet.
https://graph.facebook.com/fql?q=SELECT url, normalized_url, share_count, like_count, comment_count, total_count,commentsbox_count, comments_fbid, click_count FROM link_stat WHERE url='http://www.dn.se/kultur-noje/basta-beatrice-ask'

Från twitter (och min twittercensus-data) kan man dra ut geo-kodning för enskilda tweets (alltså de som använt GPS:en i telefonen och lagt till den informationen till tweetet) för att se exakt var person skickat twittermeddelande. I ärlighetens namn bör man nog poängtera att bara en liten minoritet av twitteranvändarna har geokodning av tweets aktiverat så de flesta tweetmeddelande dyker inte upp på en sådan här karta (eller andra liknande lösningar, som den här coola realtidskartan).




Jag medverkade på nyhetsmorgon i morse och pratade om Twittercensus och de mest retweetade twittermeddelandena under 2012. Se klippet hos TV4.
I mitten av året lanserade Europeiska Kommissionen kampanjen “Science – it’s a girl thing” med det uttalade syftet att locka fler kvinnor/tjejer till forskning och innovation. Som en del i projektet lanserades det virala fiaskot “Science – it’s a girl thing“. Jag har inte sett många youtube-klipp som har ogillats så mycket. Originalvideon togs ned, men en kopia finns. Även den med skaplig dislike-procent. Se den om du inte gjort det!
I vilket fall, en som upprördes var Curt Rice, Vice President for Research & Development på University of Tromsø. Han utlyste en tävling för att göra bättre filmer. Initiativet plockades upp av European Science Foundation som gjorde det till en officiell(are) tävling. Sagt och gjort. Vi gjorde en video med vår dotter Ada.
Nu behöver vi din hjälp med att rösta fram vårt bidrag. Inte mer än en gång per dag 🙂
I veckan pratade jag om Twittercensus och användandet av Twitter i Sverige för Aftonbladets Online Academy.

En ny funktion på Intellecta Corporates Twittercensus gör det möjligt att visualisera vem som följer ett visst konto och tvärtom. Tanken är inte primärt att identifiera exakt vilka personer det är – det är enklare att göra på Twitter självt. Istället är det intressanta att titta på inom vilka kluster man har följare och följer konton. Resultaten torde vara intressanta utifrån diskussioner om representativitet, bubblor, elitism såväl affärsnytta för företag. Jag har valt ut några olika typer av twitterkonton för att dels förklara funktionaliteten, dels visa på intressanta aspekter. Jag har inte själv gjort så mycket analys i det här läget – det finns gott om tid för det. Men jag gör några korta reflektioner på slutet.
Självklart kan du själv använda tjästen – men om du tittar på personer med väldigt många följare (>10 000) så kommer sidan att ladda och rendera långsamt. Jag rekommenderar Chrome för att göra upplevelsen så smärtfri som möjligt.
Först, några korta förklaringar. “Kartan”, “blobben”, “amöban” är en visualisering av de mest aktiva twittrarna som skriver på svenska. Drygt 50 000 är med på kartan och kriteriet är att kontot skrivit minst lika många tweets som det är dagar gammalt. Alltså en snittproduktion på minst 1 tweet om dagen.
Dessa konton har sedan visualiserats med en kraft-baserat algoritm som enkelt uttryckt gör konton som följer varandra dras samman, medan konton som inte följs skjuts bort. Mycket mer utförlig beskrivning finns här. Färgerna representerar olika kluster som är statistiskt framräknande. Totalt finns 23 sådana kluster i kartan. Vad ett kluster “är” blir en subjektiv tolkning, men när man tittar på personerna i respektive grupp är det ofta väldigt enkelt att sätta ett namn på gruppen. Christofer Laurin gått igenom alla och gett dem namn. Det är hans bild du ser här.


Nästa steg är att titta på vilka som följer ett visst konto (eller tvärtom). I bilden syns de som följer mig (@hampusbrynolf) och du kan se livegrafen här.
Som synes är mina följare nästan uteslutande befinner sig i det norra delen av grafen – och i det orangea klustret. Jag är rätt jämt fördelad mellan det västra (teknik, “bubblan”) och östra (politik, ledarskribenter, media) delen av den orangea klustret. Det stämmer också ganska bra med min egen bild. I det lila vänstra klustret (sport) finns det i stort sett ingen som följer mig, och inga i de södra regionerna.

Som synes har Göran en väldig dominans i det nordöstra delen av kartan. Sen glesas följarna ut i alla riktningar. I de södra delarna är det ingen som följer honom, i det lila sportklustret är det väldigt få och så vidare.
Om man jämför med Sanna Kallur så är skillnaden uppenbar.

Få i politik/media/journalist-kretsen följer Sanna Kallur, medan hon har höga följartal i sportklustret.
Det går även att titta på vilka konton en person följer, här är Göran Hägglunds följarprofil.

Det första och uppenbara insikten är att de olika klusten är ganska separerade från varandra. Tittar man på personer i endera kluster så följs de av person från samma område eller närliggande. Det gäller mig, det gäller Karin Pettersson eller Peter Wolodarski. Det finns alltså inte ett Twitter i Sverige, det finns fler olika. Kittet som håller samman verkar vara kändisarna, personer som följs av alla oavsett: Magnus Betner, Adam Alsing, Jonas Gardell, men även sportstjärnor av olika slag. Men även där finns tydliga skillnader i vilka kluster de är tyngst.
Vad gäller företag, såsom SJ eller ComHem, har de ganska ickerepresentativa följareprofiler. Men mer om det i ett senare inlägg.